
Architecture design of a Data Catalog system in AWS. The objective of the project is to ingest metadata from all kinds of data origins. This includes relations databases, datawarehouses, any other kind of database, data files and media such as videos, audio or images.
Given the state of the art at the moment of designing the solution, the best option has been to use Amundsen data catalog substituting its default Neo4J backend by Apache Atlas as the backend. Amundsen and Apache Atlas are both FASS. They have rather a big community in behind and can be used in combination to provide a very robust and flexible data catalog solution.
Amundsen has features that Atlas does not include. For example: it has ranked search, it provides additional fields in datasets that makes the data catalog more of a social tool. Atlas is also a Data catalog itself but its designed to be used by users who are more technical. However, Apache Atlas knowledge graph is more complete than the default Nee4j knowledge graph of Amundsen. For this reason using Apache Atlas as the backend for the knowledge graph of Amundsen provides the experience of knowledge graph modelling of Apache Atlas with the end user orientation of Amundsen, which includes a much more useful search for a large team.
Data Catalog as solution to any client use case
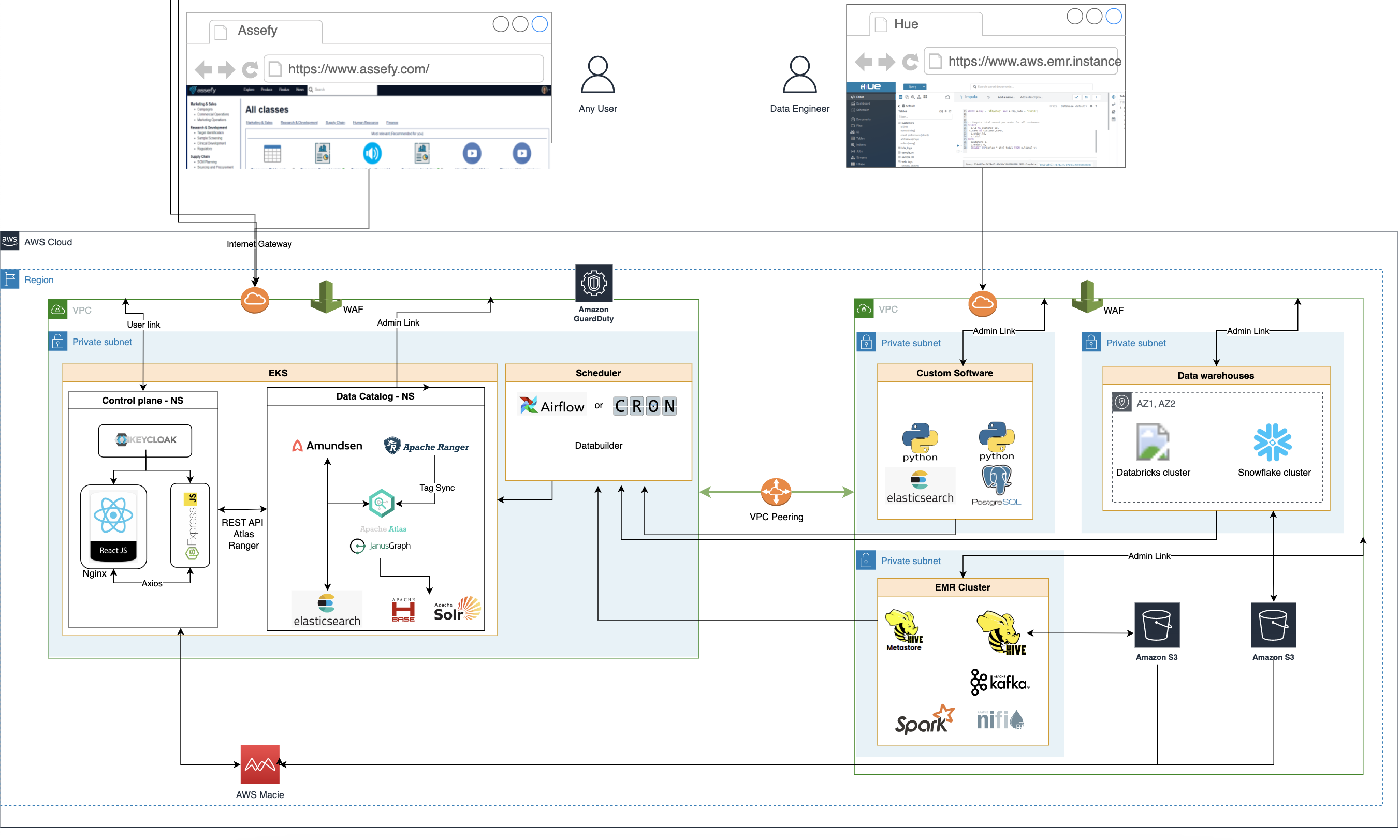 The key point of the solution is the way the metadata is ingested. Apache Atlas enables the user to ingest metadata via REST API or it also has the possibility to use a Kafka Topic to ingest the metadata automatically when there’s any update. The limitation of this approach is that the events of the Kafka topic have to be sent from a component of the Hadoop ecosystem, being Hive Metastore the most indicated component to target. Given the influence of Hive Metastore in other data catalog solutions a possibility could be to use a Hive Metastore on the side of the client and use it as a bridge for Apache Atlas. However, Amudsen has a Python library called databuilder that allows to ingest metadata from a large list of data sources without the need of having to use a Hive Metastore as a bridge. This makes the databuilder library the preferred option for the architecture.
The key point of the solution is the way the metadata is ingested. Apache Atlas enables the user to ingest metadata via REST API or it also has the possibility to use a Kafka Topic to ingest the metadata automatically when there’s any update. The limitation of this approach is that the events of the Kafka topic have to be sent from a component of the Hadoop ecosystem, being Hive Metastore the most indicated component to target. Given the influence of Hive Metastore in other data catalog solutions a possibility could be to use a Hive Metastore on the side of the client and use it as a bridge for Apache Atlas. However, Amudsen has a Python library called databuilder that allows to ingest metadata from a large list of data sources without the need of having to use a Hive Metastore as a bridge. This makes the databuilder library the preferred option for the architecture.
The value of the proposed architecture resides in that it is relatively easy to deploy our solution to any cloud that a client might be already using. This is possible by deploying the an already designed data catalog solution that uses Amundsen and then fin-tune the solution to ingest the specific metadata for that client with the help of the databuilder Python library.
The value is also in the fact that we also provide a React web UI that is even more user friendly than the Amudnsen one. This allows to add more functionalities and features to classify, share, rate and search the metadata, while at the same time, preserving the access to control planes from Apache Atlas or Apache Ranger for other more technical users inside of the team. Using Apache Atlas enables us to expand the data catalog fields to support all the new functionalities that the React application feature.
For those interested in how Apache Atlas gives support to Amundsen as a backend I have created a Google Sheets that contains each of the Types that Atlas Creates for Amundsen on top of the default ones: Amundsen Types in Apache Atlas