

Applying Data Mesh for Fintech Industry (Part1)
If you are working in the area of data and specially if you are a data engineer or data architect you probably have heard about Data Mesh as a paradigm shift or improvement over the well know data hub or data lake paradigms. Data mesh it is certainly becoming a buzz word that despite being heard more and more, few people yet, at the time of writing this article, truly know.
To begin with, Data mesh can be considered a the 4th generation of the data management systems were the previous generations are: 1st the data warehouses, 2nd the appearance of Big Data and the Data Lakes and 3rd are the Lambda and Kappa architecture where the Streaming of Data in near-real time or real time is included in the Datahub.
Certainly the power of the Big Data Technologies that appeared with the exponential growth of US-Tech companies such as Google, Facebook, Microsoft, Netflix and Airbnb among. This made to to all companies to take advantage of these powerful technologies and to rely on big Datahubs and Data Lakes to do single shoot solution. This is to process all data from the company and deliver it to multiple internal or external clients. This has been a way to solve the problem of processing more and more data until now but big organisations are starting to see how complex is to create such a large single team to give support to huge Data Hubs while ensuring the data quality and its availability.
To solve these problems organisational problems and taking into account that there’s not a big technological leap in how do we manage data, the concept of Data Mesh is born. It basically consists on separating the data team in domains that can be differentiated, which in most of the cases it is different business domains. This creates the concept of data as a product, where each team is responsible to be compliant with an SLO over their data, provide sample of datasets and to provide a way to interact with their data according to a defined general standard, so other teams can consume those data as if it was a product instead of requiring being experts of each domain.
Data Mesh Architectural Quantum
Data mesh introduces data as a product as its architectural quantum. For, which data is logically separated into domains. Each node or domain of the mesh includes three structural components that give place to the architectural quantum:
- Code: it includes the code of the pipeline, the code of the APIs to access data, and the code to enforce compliancy, control policies, provenance, data lineage, etc.
- Data and Metadata: the same data can be stored in different database types to allow a convenient consumption depending on the use case. The metadata is for quality metrics, traits, access control policies, etc.
- Infrastructure: all the infrastructure that allows data to be consumed as a product as well as all the related store for the data and its metadata.
Data Mesh Example
For our example, we are going to see how to apply the data mesh framework in the context of a fintech product that recommends financial assets/products to end users.
In this post we will have an overview over data taken from social networks for which we will analyse the sentiment of assets over the time. Then we will also have the data that is taken from online repositories that contain price, volume and other technical data from assets. So in this example it is straightforward to come up with a two domains. One for sentiment data which involves using AI tools and one domain for the technical data, which involves dealing with paid external APIs.
The below figure shows the example. It is clear that data mesh is implemented by means of the current technologies and that we even could say that inside of each domain concepts such as data lake and ETL can be found. However, the data mesh paradigm shift resides into federating instead of centralising.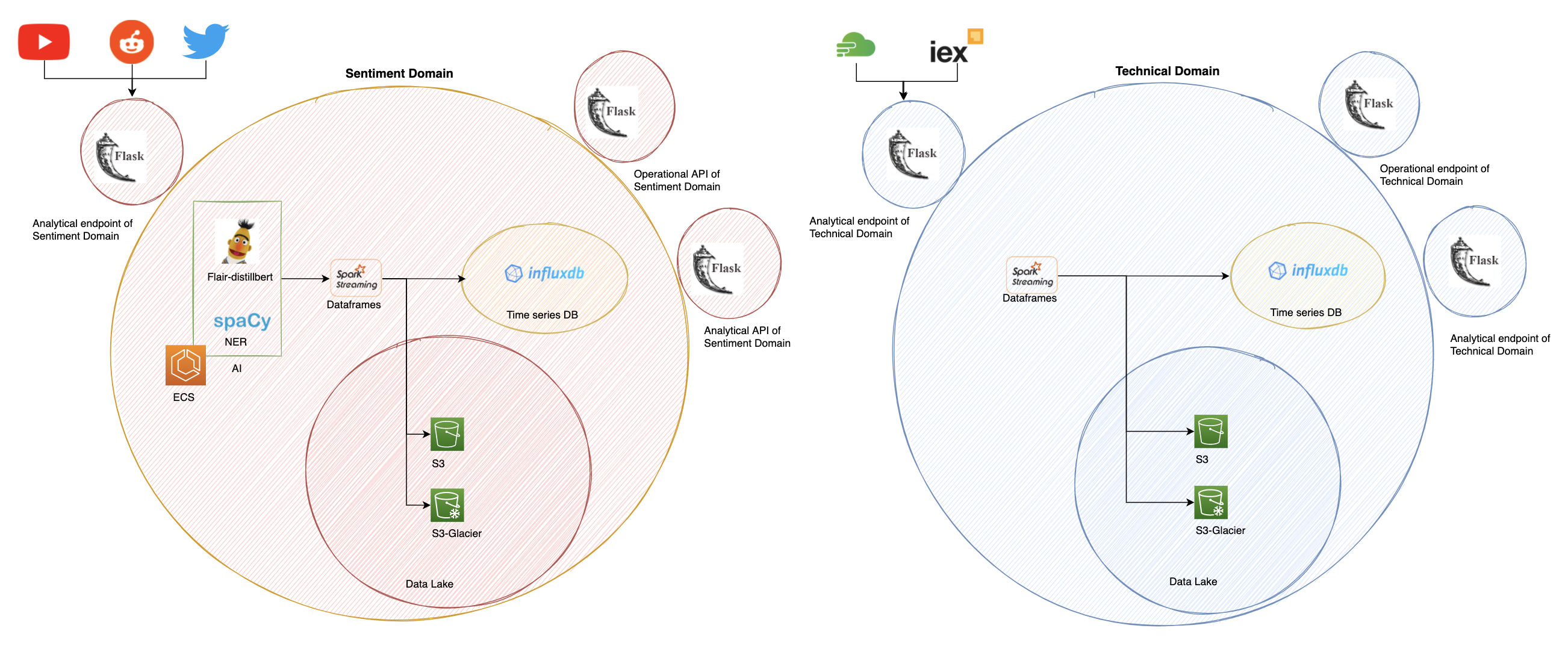 As a consequence of this decentralisation, each domain has to work on providing a solid API to interact with. It has to provide endpoints for its interoperability; where in our example this would include operations such as adding an asset to be tracked, removing and asset or adding an influencer into the list of experts to follow. The domain also has to provide analytical data endpoints. In our example, these ones are giving the functionality of getting analytics of the percentage of positive tweets over a topic in a lapse of time, how many users commented on an asset with respect to last year, etc. At the same time the ingestion of data providing from social networks like Youtube or Tweeter for posterior sentiment analysis also can be defined as an analytical endpoint.
As a consequence of this decentralisation, each domain has to work on providing a solid API to interact with. It has to provide endpoints for its interoperability; where in our example this would include operations such as adding an asset to be tracked, removing and asset or adding an influencer into the list of experts to follow. The domain also has to provide analytical data endpoints. In our example, these ones are giving the functionality of getting analytics of the percentage of positive tweets over a topic in a lapse of time, how many users commented on an asset with respect to last year, etc. At the same time the ingestion of data providing from social networks like Youtube or Tweeter for posterior sentiment analysis also can be defined as an analytical endpoint.
Data as a Product DaaP
As it has been exposed, in data mesh framework the main key concept to implement this decentralisation is the data as a product or DaaP. Each domain provides to the rest of domains data products that need to comply with the following requirements:
- Discoverable: this is done by means of a registry or data catalogue that includes all the data products with their corresponding meta data. Their responsible, origin of data, data lineage, available sample datasets, etc. So each data product has to register itself to a centralised data catalogue to be easily discovered.
- Addressable: the data product has a unique address following a general standard within the whole system. This means that despite having a polyglot environment where data will be in different formats such as Parquet, CSV, JSON, etc. addressability will make the interaction with each domain to be frictionless.
- Trustworthy: here the shift is about delivering a product so data products should respect a Service Level Objective SLO for the truthfulness of the data. This includes determining how accurate are data with respect to the reality by quantifying the error and using probability metrics.
- Self-describing: DaaP includes the philosophy of a product so in this sense the product should also be as easy to use as possible. This minimises the time spent by data scientists, data engineers and other data consumers to begin using data from the domain. To put it into another way, data products have to be self-served assets.
- Inter-operable: despite data being decentralised and polyglot, the standardisation through a global governance should make possible operations such as joins in between databases located in different domains. Here topics such as identifying polysemes, use of common event format with tools such as CloudEvents or databases address conventions are included.
- Secure: in a decentralised environment each domain has the ability to apply finer granularity to each data product. However, making use of SSO and RBAC/ABAC policies can make more convenient the access to the data products that will be in different domains.
Federated Computational Governance
For the purpose of federating, we can define what is called a federated computational governance, which is in charge of defining the SLOs for each domain and to define the standards for the interoperability of data across domains. Members of this group are representatives of each of the domains where the each domain can be an SME with its incentives and or product owners of teams of the same enterprise.
In a next article we will describe with more detail how the federated computational governance defines the SLOs and how it would work in our example. It will also be explained other important aspects of data mesh such as its multiple planes to serve different profile users.

