

Streaming in Confluent KsqlDB: Modifying AVRO Schema
In the context of streaming applications Kafka has been a very used technology to solve real time and exactly-once-processing problems by many big and medium companies. It also has been used as a temporary logs in which all applications could benefit from brokerage and read from multiple destinations the same incoming data. With the introduction of cloud services such as Kinesis, MSK, Firehose, etc. infrastructure management has been reduced and with so the associated costs. This has been called “the democratization of streaming” because it has allowed smaller companies to use these powerful technologies without spending huge figures in large IT teams. However, there still was a caveat in this matter: programming a Kafka application was reduced to using Java and the development complexity was higher than using Spark Structured Streaming or even Flink or Storm. Moreover, the later frameworks provide much more powerful calls to manipulate data on the fly. Whether in form of microbatches such as the case of Spark Structured Streaming and Storm in its Trident version, or in the form of real time such as in Flink or Storm by default. Gives this, it is very common to see architectures with Kafka only being at the front of the data pipeline gathering and storing incoming data tuples as the fastest technology and coupling some other more friendly framework to process and manipulate data from Kafka even if after the Kafka step there only was a single application.
However, with the introduction of ksqlDB this default architecture is very likely to change for many of the forecomming projects. KsqlDB gives the programmer a SQL-like interface to operate with Kafka Streams. This means that by typing SQL queries it is possible to manipulate how the streams make data transformations to the incoming data into the Kafka cluster. With this possibility, if data transformations doesn’t need to be very sophisticated, it is possible to skip using other frameworks such as Spark Streaming or Flink and do everything inside of the same Kafka cluster.
A very interesting characteristic of Kafka in conjunction with the Confluent Schema registry is the possibility to report changes in the forecoming data and thus being able to support those new formed data correctly. In this post we’ll see how to locally set up Kafka, code a simple application and change the data format what will require from a change in the Schema Registry. Furthermore, the special point will be using the Confluent Control Center instead of the command line for common tasks such as monitoring the Kafka cluster, the processed data and looking at the Schema changes.
Configuration of the environment
Let’s first configure the environment. Basically we need to download and configure Java and Kafka but for Kafka we will be using the Confluent Platform, which gives the potential of ksqlDB and the Confluent Control Center. Notice that the later feature is a paid feature but there is free licence when using it in a Kafka cluster with a single Kafka broker.
https://kafka.apache.org/downloads
Install Java
It is very likely that you already have Java installed. In this tutorial java 1.8 has been used so make sure you have this or a later version by typing:
java -version
If no java is installed in your machine you can follow the instructions here.
Install Confluent Platform
Now install the Confluent platform. Remember that this already has everything related to Kafka included in the same folder.
https://www.confluent.io/download/
make a soft link to access to the latest version and export the PATH variable so you have the needed binaries conveniently accessible.
ln -s confluent-6.0.0/ confluent export PATH=${PATH}:/Users/david/bigdata/confluent/bin kafka-topics
Now let’s install the standalone Confluent CLI (command line interface). Start and stop and interrogate the state of the Confluent platform.
curl -L https://cnfl.io/cli | sh -s -- -b /Users/david/bigdata/confluent/bin
Check the confluent command is well pointed.
./confluent
Set the confluent environment variable.
export CONFLUENT_HOME=/Users/david/bigdata/confluent
(export PATH=”${CONFLUENT_HOME}/bin:$PATH”)
(For more information go: here)
Running the Confluent Platform and testing it
confluent local services ksql-server start
confluent local services ksql-server status
confluent local services status
The local commands are intended for a single-node development environment only
NOT for production usage. https://docs.confluent.io/current/cli/index.html
Using CONFLUENT_CURRENT: /var/folders/1w/j7gzxdm92h154vzv04th5v1c0000gn/T/confluent.553577
Connect is [DOWN]
Control Center is [DOWN]
Kafka is [UP]
Kafka REST is [DOWN]
ksqlDB Server is [UP]
Schema Registry is [DOWN]
ZooKeeper is [UP]
Now that the ksqlDB server is up let’s start to play a bit with the system:
Create a topic in Kafka Cluster.
kafka-topics --zookeeper localhost:2181 --create --partitions 1 --replication-factor 1 --topic USERS
Now in a separate terminal turn the ksqlDB server by typing ksql. Then perform the following commands. You’ll see that the commands are very self-explanatory. However, if more information is required you can consult a list of ksql commands here.
ksql> list topics;
>;
Kafka Topic | Partitions | Partition Replicas
—————————————————————
USERS | 1 | 1
default_ksql_processing_log | 1 | 1
test | 1 | 1
kafka-console-producer --broker-list localhost:9092 --topic USERS
>Alice,US
>Bob,GB
>Carole,AU
>Dan,US
ksql> print 'USERS'
>;
Key format: ¯\_(ツ)_/¯ – no data processed
Value format: KAFKA_STRING
rowtime: 2020/11/15 09:15:04.592 Z, key: <null>, value: Carole,AU
rowtime: 2020/11/15 09:15:13.726 Z, key: <null>, value: Dan,US
^CTopic printing ceased
ksql> print 'USERS' from beginning;
Key format: ¯\_(ツ)_/¯ – no data processed
Value format: KAFKA_STRING
rowtime: 2020/11/15 09:13:15.670 Z, key: <null>, value: Alice,US
rowtime: 2020/11/15 09:14:27.093 Z, key: <null>, value: Bob,GB
rowtime: 2020/11/15 09:15:04.592 Z, key: <null>, value: Carole,AU
rowtime: 2020/11/15 09:15:13.726 Z, key: <null>, value: Dan,US
ksql> print ‘USERS’ from beginning limit 2;
Key format: ¯\_(ツ)_/¯ – no data processed
Value format: KAFKA_STRING
rowtime: 2020/11/15 09:13:15.670 Z, key: <null>, value: Alice,US
rowtime: 2020/11/15 09:14:27.093 Z, key: <null>, value: Bob,GB
Topic printing ceased
ksql> print 'USERS' from beginning interval 2 limit 2;
Key format: ¯\_(ツ)_/¯ – no data processed
Value format: KAFKA_STRING
rowtime: 2020/11/15 09:13:15.670 Z, key: <null>, value: Alice,US
rowtime: 2020/11/15 09:15:04.592 Z, key: <null>, value: Carole,AU
Topic printing ceased
ksql>create stream users_stream (name VARCHAR, countrycode VARCHAR) WITH (KAFKA_TOPIC='USERS', VALUE_FORMAT='DELIMITED');
ksql> list streams;
Stream Name | Kafka Topic | Format
—————————————————————
KSQL_PROCESSING_LOG | default_ksql_processing_log | JSON
USERS_STREAM | USERS | DELIMITED
SET 'auto.offset.reset'='earliest';
ksql> list streams;
select name,countrycode from users_stream EMIT CHANGES;
select name,countrycode from users_stream EMIT CHANGES limit 1;
select countrycode, count(*) from users_stream group by countrycode EMIT CHANGES;
+————————————-+————————————-+
|COUNTRYCODE |KSQL_COL_0 |
+————————————-+————————————-+
|GB |1 |
|AU |1 |
|US |2 |
ksql> drop stream if exists users_stream delete topic;
show streams,
show topics;
Coding the application
We already have played somehow with the ksqlDB. Created a topic, published data to the topic and even created and dropped streams. Now it’s time to make the further step and see how to use the Confluent Control Center and how to apply changes to an AVRO schema.
First of all,, let’s stop the confluent services and start them again. But this time we are going to start all them by simply specifying start without referring to anyone in special.
confluent local services start
To access the Confluent Control Center, go to your browser and type localhost using the 9021 port. A simple resume of the clusters will appear. In this case there only one cluster with a single broker.
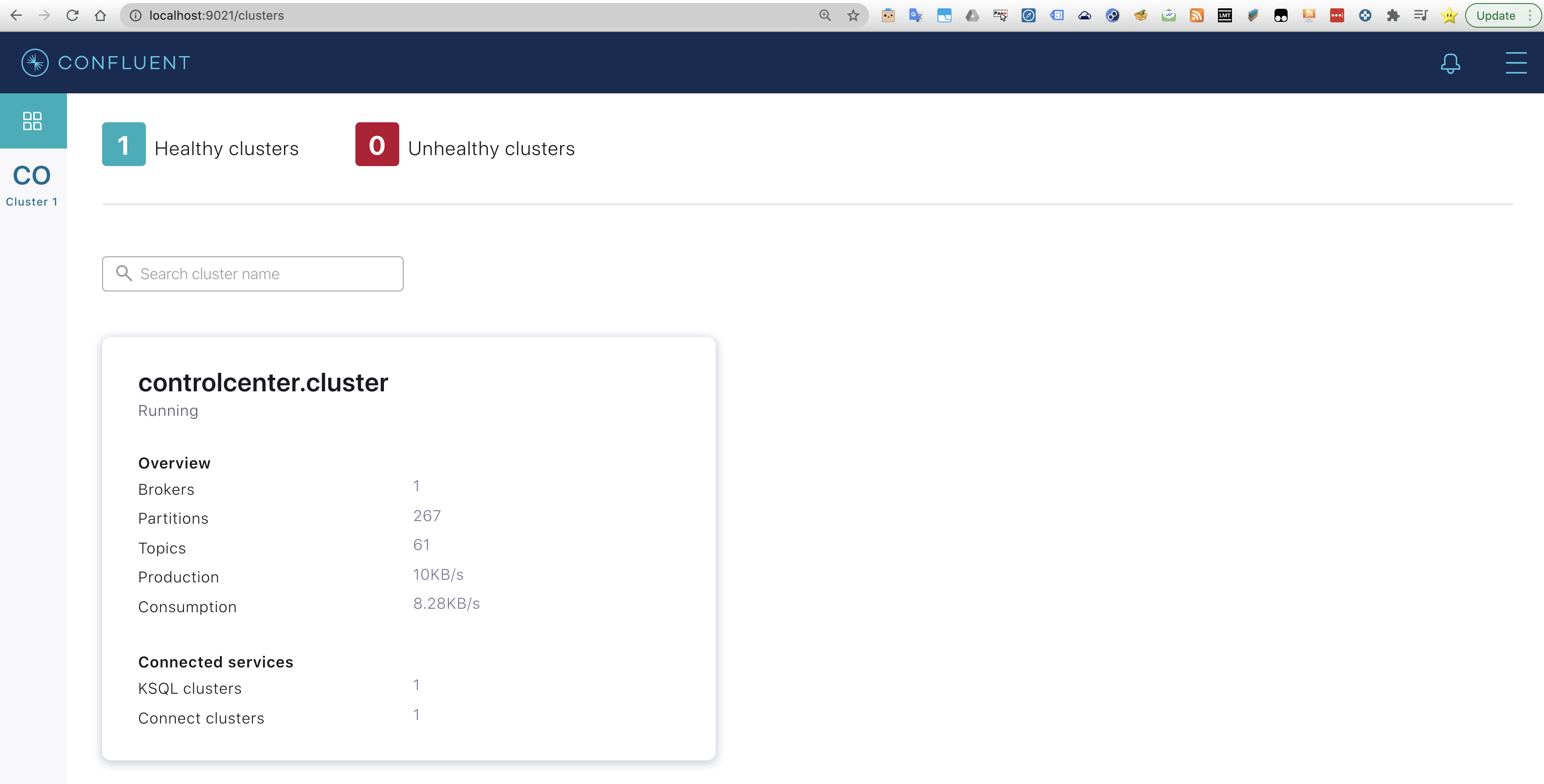
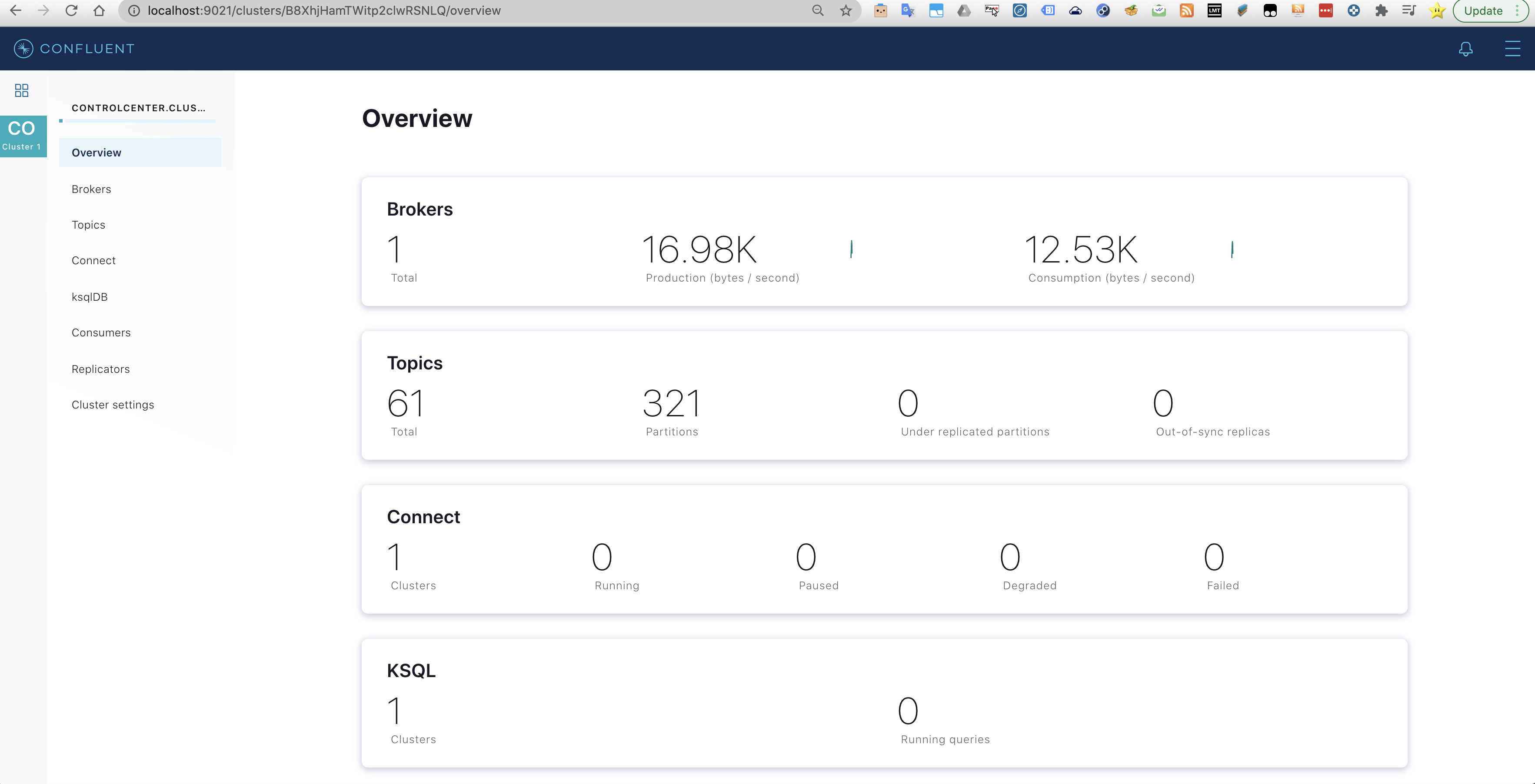
Looking into the menu more detailed information regarding the Kafka cluster and the ksqlDB is revealed.
Let’s create a new topic, which will represent complains from the users.
kafka-topics --zookeeper localhost:2181 --create --partitions 1 --replication-factor 1 --topic COMPLAINTS_AVRO
Now let’s create a stream for the complains topic and insert a record in AVRO format. Finally, we describe the stream.
ksql create stream complaints_avro with (kafka_topic='COMPLAINTS_AVRO', value_format='AVRO'); kafka-avro-console-producer --broker-list localhost:9092 --topic COMPLAINTS_AVRO --property value.schema='{ "type": "record", "name": "myrecord", "fields": [ {"name": "customer_name", "type": "string" }, {"name": "complaint_type", "type": "string" },{"name": "trip_cost", "type": "float" }, {"name": "new_customer", "type": "boolean"} ] }' << EOF {"customer_name":"Carol", "complaint_type":"Late arrival", "trip_cost": 19.60, "new_customer": false} EOF ksql> describe extended complaints_avro;
Name : COMPLAINTS_AVRO
Type : STREAM
Timestamp field : Not set – using <ROWTIME>
Key format : KAFKA
Value format : AVRO
Kafka topic : COMPLAINTS_AVRO (partitions: 1, replication: 1)
Statement : CREATE STREAM COMPLAINTS_AVRO (CUSTOMER_NAME STRING, COMPLAINT_TYPE STRING, TRIP_COST DOUBLE, NEW_CUSTOMER BOOLEAN) WITH (KAFKA_TOPIC=’COMPLAINTS_AVRO’, SCHEMA_ID=1, VALUE_FORMAT=’AVRO’);
Field | Type
———————————-
CUSTOMER_NAME | VARCHAR(STRING)
COMPLAINT_TYPE | VARCHAR(STRING)
TRIP_COST | DOUBLE
NEW_CUSTOMER | BOOLEAN
———————————-
Local runtime statistics
————————
(Statistics of the local KSQL server interaction with the Kafka topic COMPLAINTS_AVRO)
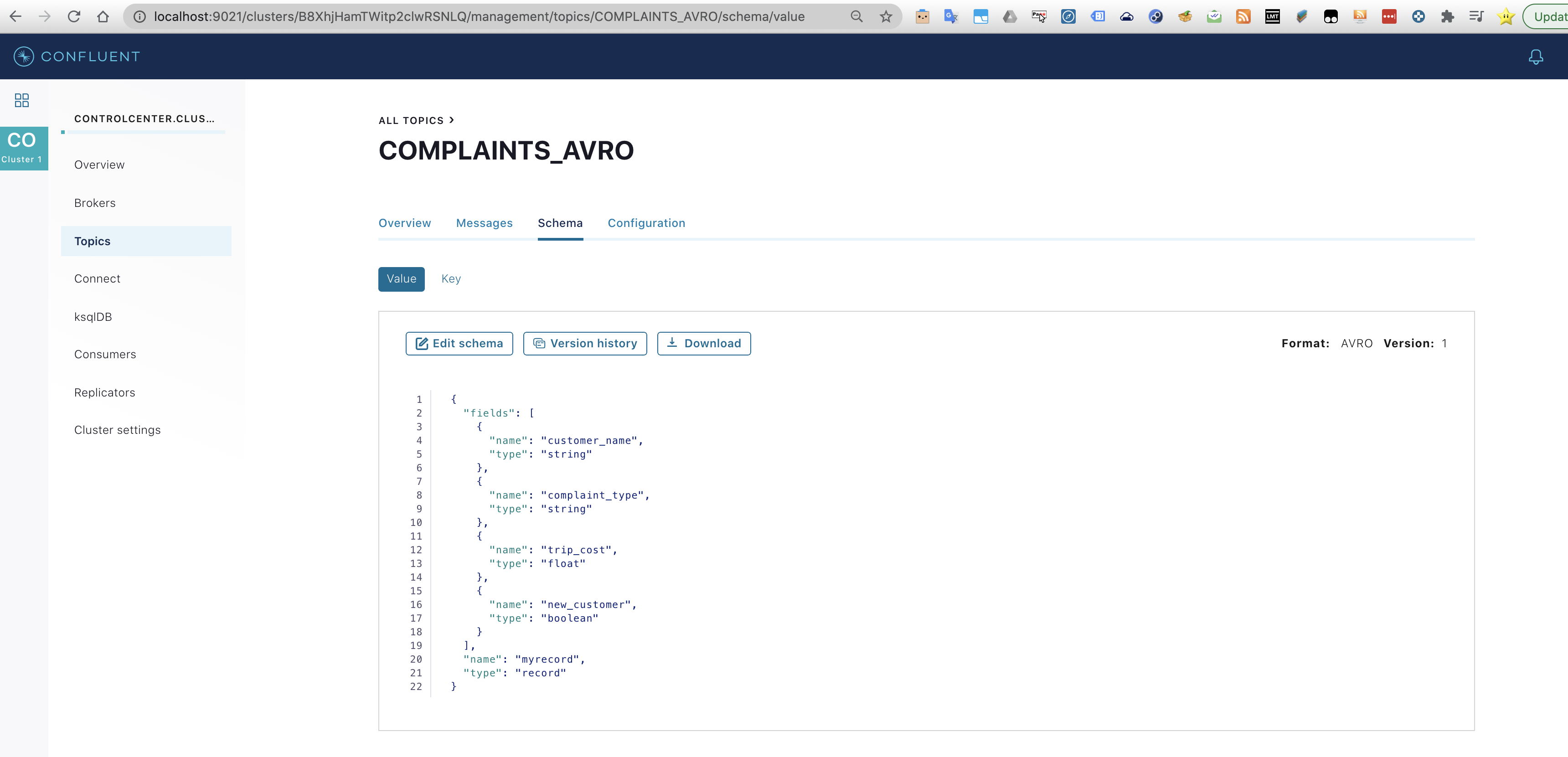
The topic has been created and the schema can be seen in the Confluent Control Center (CCC). Mind the available options regarding to the schema.
Now let’s create the version 2 of the schema by executing the following command.
kafka-avro-console-producer --broker-list localhost:9092 --topic COMPLAINTS_AVRO --property value.schema=' {"type": "record","name": "myrecord","fields": [{"name": "customer_name", "type": "string" }, {"name": "complaint_type", "type": "string" }, {"name": "trip_cost", "type": "float" }, {"name": "new_customer", "type": "boolean"}, {"name": "number_of_rides", "type": "int", "default" : 1}]}' << EOF
{"customer_name":"Ed", "complaint_type":"Dirty car", "trip_cost": 29.10,"new_customer": false, "number_of_rides": 22}
EOF
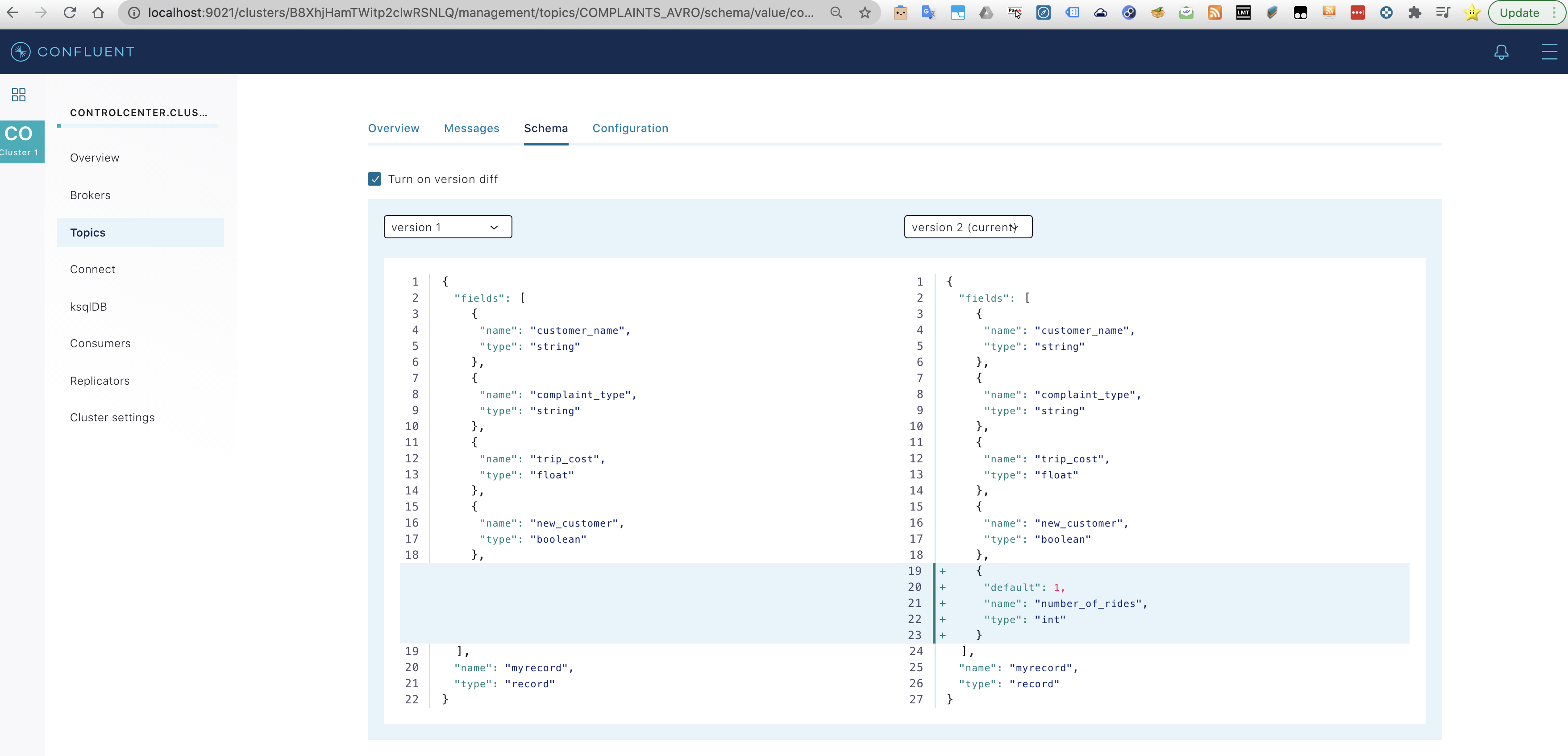
And when going back to the CCC it is possible to see the schema version 2. Notice how it is possible to make a diff between the different versions. In this case we only have the two created versions.
Versions can also be retrieved by applying curl command over the CCC.
curl -s -X GET http://localhost:8081/subjects/COMPLAINTS_AVRO-value/versions
[1,2]%
Let’s have a look to the streams to understand what’s the behaviour of them when we change the schema.
describe the old stream:
describe complaints_avro;
You’ll see that despite the avro schema was changed the old stream still treat the data according to the first schema.
To operate with the second or newer schema let’s create a new stream:
create stream complaints_avro_v2 with (kafka_topic='COMPLAINTS_AVRO', value_format='AVRO');
Now describe the newer stream to discover that it takes into account the new field fo the updated schema
describe complaints_avro_v2;
An additional check is to directly consult both streams:
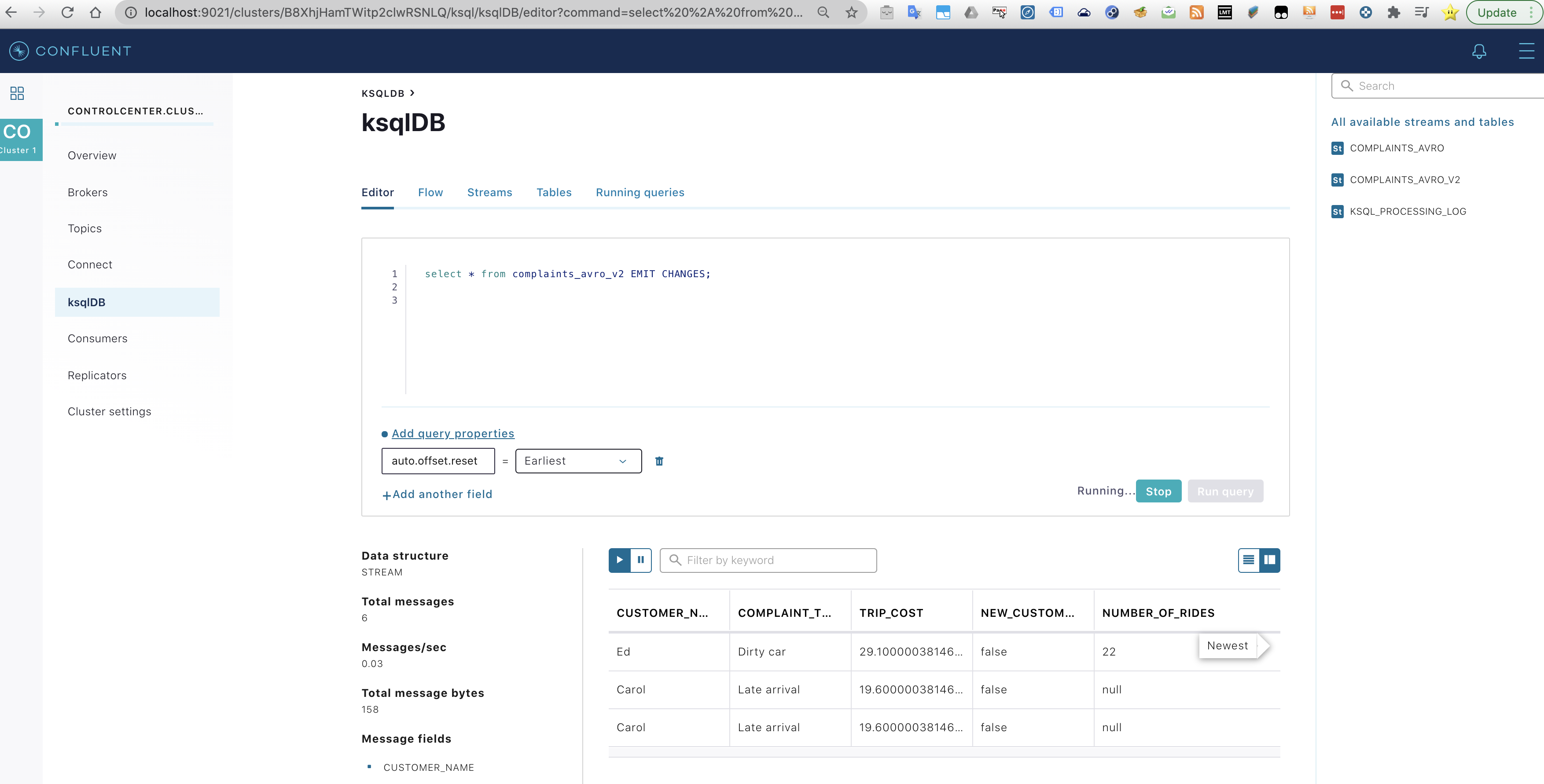
ksql> select * from complaints_avro EMIT CHANGES;
+—————–+—————–+—————–+—————–+
|CUSTOMER_NAME |COMPLAINT_TYPE |TRIP_COST |NEW_CUSTOMER |
+—————–+—————–+—————–+—————–+
^CQuery terminated
ksql> select * from complaints_avro_v2 EMIT CHANGES;
+————-+————-+————-+————-+————-+
|CUSTOMER_NAME|COMPLAINT_TYP|TRIP_COST |NEW_CUSTOMER |NUMBER_OF_RID|
| |E | | |ES |
+————-+————-+————-+————-+————-+
^CQuery terminated
If no users where shown it’s because you closed the ksql session and you lost the environment configuration. Just type again:
SET 'auto.offset.reset'='earliest';
You can achieve the same effect by using the Confluent Control Center. Set the knobs just like the image below:
Conclusions
The installation and setup of the Confluent Platform has been extremely easy. The idea of packing everything into a folder and being able to execute a Kafka cluster in local with Kafka streams and providing the ksqlDB interface it’s really a game changer. Going to a cluster installation would be much less easy but despite that, the ksqlDB represents that so called democracy into all companies being able to use such a powerful technology without needing to use other total privative licence that are expensive.
An interesting feature of ksqlDB is the possibility to define UDFs of UDAFs when the transformations we want to make to the streams are so complicated that there are not predefined functions available. This adds even more power to ksqlDB and its possibilities for the architect to drop off from the data pipeline other technologies such as Flink, Storm or Spark Structured Streaming.

